The Latent Color Subspace: Emergent Order in High-Dimensional Chaos
Inside FLUX’s VAE latent space, we uncover a structured color subspace aligned with Hue, Saturation, and Lightness, enabling training-free color control via closed-form latent manipulation.
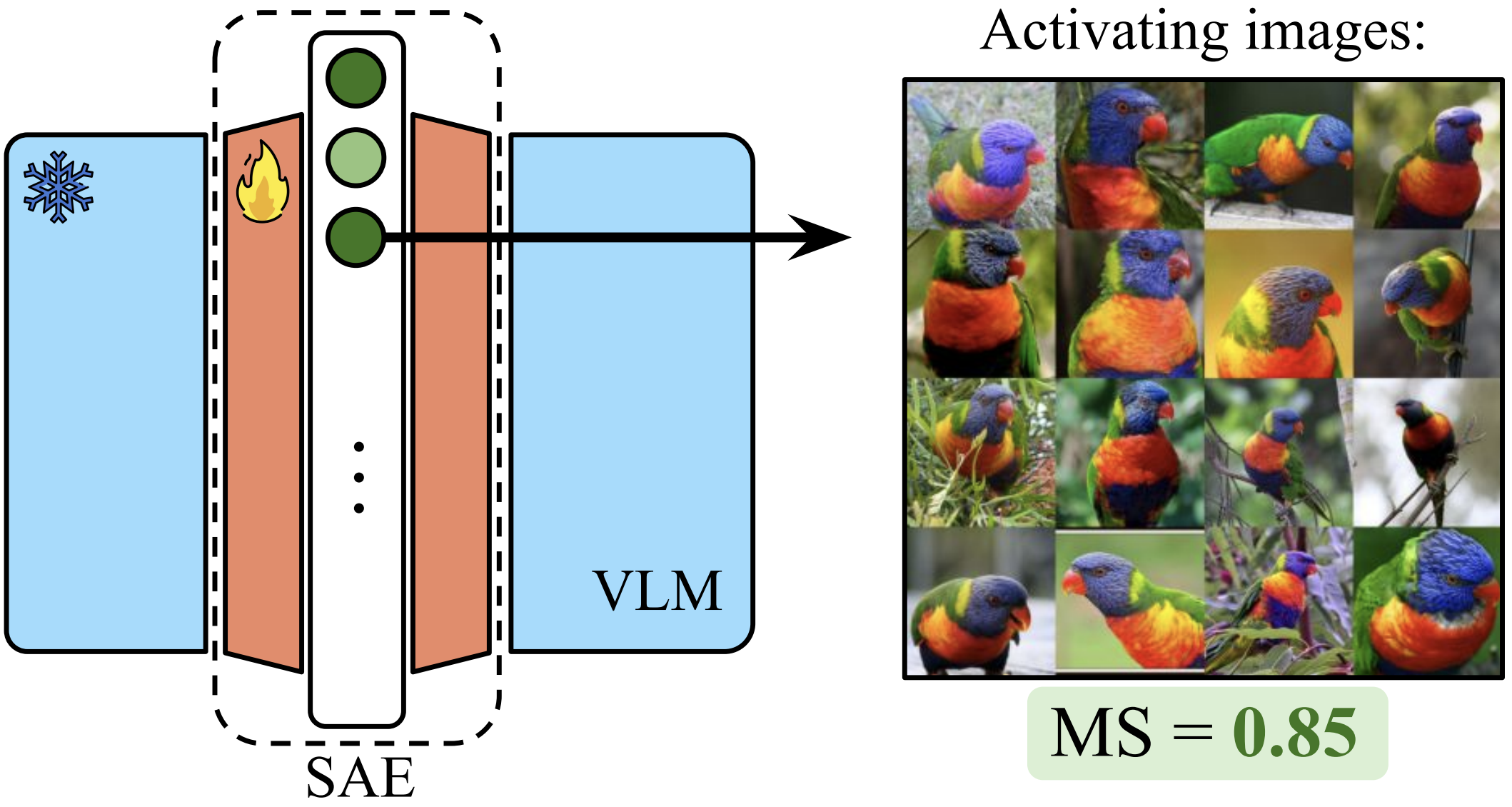
Sparse Autoencoders Learn Monosemantic Features in Vision-Language Models
With the proposed Monosemanticity Score, we show that SAEs in VLMs discover monosemantic, interpretable features, enabling fine-grained control over learned representations.
Stitch: Training-Free Position Control in Multimodal Diffusion Transformers
Stitch is a training-free method for controlling spatial positioning in modern text-to-image models via attention constraints, splitting generation into sub-regions and stitching them together.
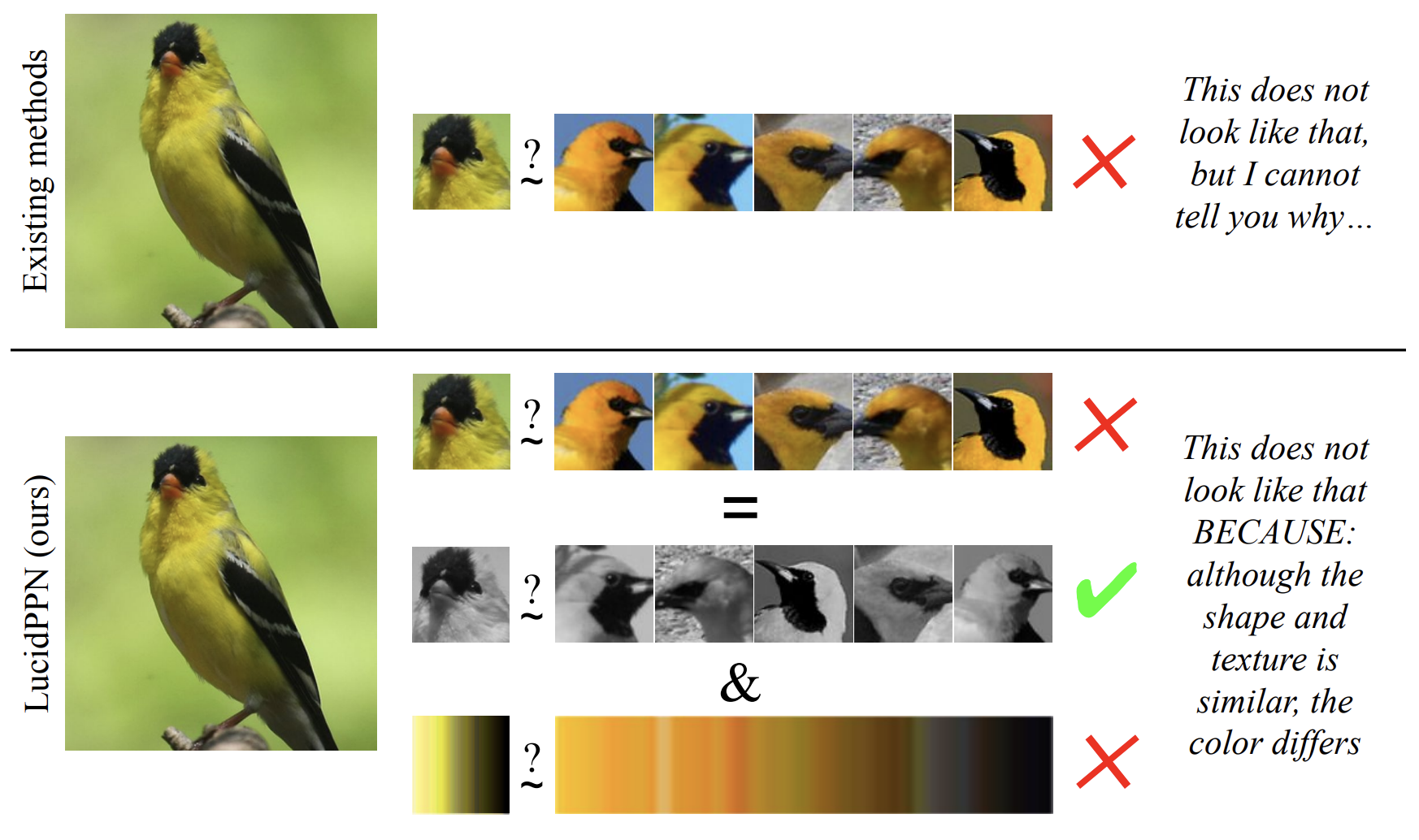
LucidPPN: Unambiguous Prototypical Parts Network for User-centric Interpretable Computer Vision
LucidPPN introduces an interpretable prototypical parts-based method that provides clear, unambiguous visual explanations by disentangling color from all other features used by the network.
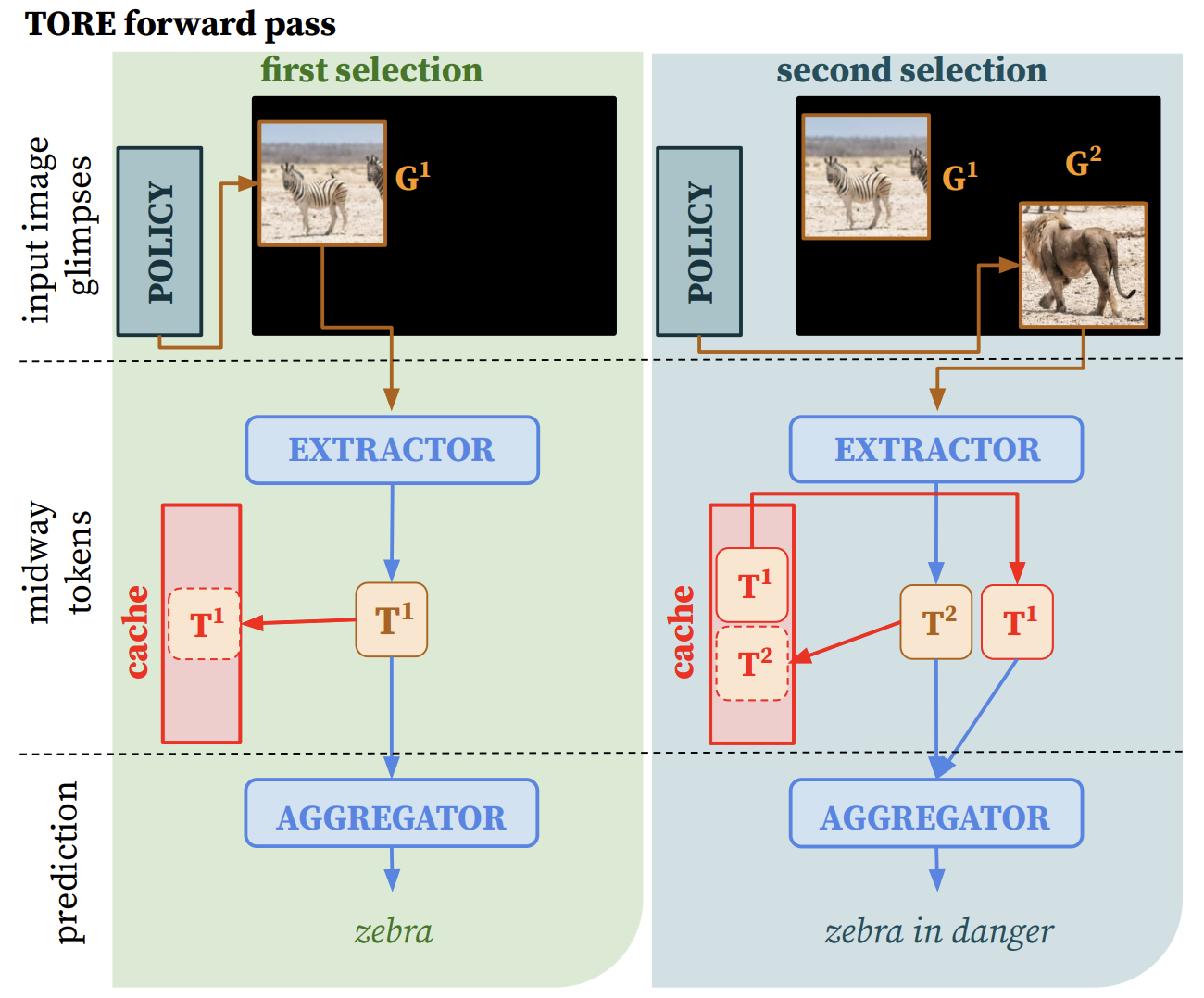
TORE: Token Recycling in Vision Transformers for Efficient Active Visual Exploration
TORE is a token recycling mechanism, improving efficiency in active visual exploration by reusing informative tokens across processing steps.